| 저자(저서) | 라이언 미첼 (<Instant Web Scraping with Java>) |
| 옮긴이(역서) | 한선용 (<한 권으로 끝내는 Node &Express>, <자바스크립트를 말하다> 외 다수> |
|
펴낸 곳(펴낸이) |
한빛미디어(김태헌) |
| 판(쇄) | 초판 2016년 12월 1일 |
| 리뷰 or 감상 | |
|
웹 크롤링(스크레이핑)을 처음 접하는 내가 보기에는 수준은 중간 정도 인 것 같다. 전반적인 내용들과 큰 그림(?)을 그려주기는 하나 확실히 분량이 작은 책이라 디테일은 아쉽다(욕심인가?) 챕터 12와 같이 깨알 핵심들로 보이는 내용들(법적 규제 등)도 간혹 등장하여 이미 크롤링이 익숙한 사람도 알아두면 좋을 내용으로 보인다
시간이 없어서 다 읽지는 못하겠다면 14.5 장만 읽고 기억해도 좋을 듯 하다. 마치 좋은 질문은 좋은 대답(결과)를 만든다는 말처럼 웹크롤링을 함에 있어서 기본이 되는 내용이라는 생각이 든다. |
|
목차
Part I 스크레이퍼 제작
CHAPTER 1. 첫 번째 웹 스크레이퍼
CHAPTER 2. 고급 HTML 분석
CHAPTER 3. 크롤링 시작하기
CHAPTER 4. API 사용
CHAPTER 5. 데이터 저장
CHAPTER 6. 문서 읽기
Part II 고급 스크레이핑
CHAPTER 7. 지저분한 데이터 정리하기
CHAPTER 8. 자연어 읽고 쓰기
[데이터 요약] https://oberlife.tistory.com/288
CHAPTER 9. 폼과 로그인 뚫기
CHAPTER 10. 자바스크립트 스크레이핑
CHAPTER 11. 이미지 처리와 텍스트 인식
CHAPTER 12. 스크레이핑 함정 피하기
CHAPTER 13. 스크레이퍼로 웹사이트 테스트하기
CHAPTER 14. 원격 스크레이핑
CHAPTER N(14.5). 미래를 향해
https://oberlife.tistory.com/287
예제 소스 : https://git.io/vXyT2
방법 변경 전
이 책에 대하여
웹 스크레이핑이란?
- 이론적 : 데이터를 수집하는 작업 전체(단, API를 활용하거나 사람이 직접 웹 브라우저를 조작하는 방법은 제외)
- 현실적 : 데이터 분석과 정보 보안 같은 다양한 프로그래밍 테크닉과 기술을 포괄
왜 웹 스크레이핑을 써야 할까요?
1) 오직 브라우저만 사용해 인터넷에 접근한다면 수많은 가능성을 놓치고 있는 것
2) 다량의 데이터를 수집하고 처리하는 데 뛰어남
3) 수집된 데이터베이스에서 수천, 심지어 수백만 페이지를 즉시 볼 수 있습니다.
#무언가를 찾을 때 고생한 기억들이 떠올랐.. 내가 원하는 정보만 빼낼 수 있다면? (ex, 사내 웹, 구글링 등)
Part 1. 스크레이퍼 제작
- 웹 스크레이핑은 비교적 적은 투자로 엄청난 소득을 올릴 수 있는 환상적인 분야이다.
- 여기서 다룰 내용
1) 도메인 이름을 받고 HTML 데이터를 가져옴
2) 데이터를 파싱해 원하는 정보를 얻음
3) 원하는 정보를 저장
4) 필요하다면 다른 페이지에서 이 과정을 반복함
CHAPTER 1. 첫 번째 웹 스크레이퍼
- 웹 서버에 특정 페이지를 요청 : GET
- HTML 결과 획득
- 원하는 콘텐츠(데이터) 추출
1.1 연결
- 파이썬의 urllib 사용(표준 파이썬 라이브러리)
: 웹을 통해 데이터를 요청, 쿠키를 처리, 헤더를 바꾸는 함수 등
- urlopen : 네트워크를 통해 원격 객체를 얻음
1.2 BeautiulSoup 소개
- 잘못된 HTML을 수정하여 쉽게 탐색할 수 있는 XML 형식의 파이썬 객체로 변환
1.2.1 BeautiulSoup 설치
#작업 중 날라감. 생략.
1.2.2 BeautiulSoup 실행

다른 사이트 한번 시도

None?? h1 태그가 없어서 그런거 같다.
소스보기로 h2태그 확인 재시도

확인 완료
1.2.3 신뢰할 수 있는 연결
- 웹 스크레이핑에서 가장 좌절스러운 경험은 스크레이퍼를 실행해놓고 모든 데이터가 데이터베이스에 저장되어 있길 꿈꾸며 잠들었는데, 다음 날 일어나보니 자리를 뜨자마자 스크레이퍼가 예기치 못한 데이터 형식에 부딪혀 에러를 일으키곤 멈춰 있을 때이다.
# 예외 상황에 대한 대비가 필수

# 해당 예제의 일부 import 잘못되어있음
- 존재하지 않는 태그에 접근을 시도하면 BeautifurlSoup는 None 객체를 반환
: 문제는 None 객체 자체에 태그가 있다고 가정하고 그 태그에 접근하려 하면 AttributeError 발생
ex)


- 스크레이퍼를 만들 때는 코드의 전반적 패턴에 대해 생각해야 예외도 처리하고 읽기도 쉽게 만들 수 있다.
- 코드 재사용을 고려할 때 아래와 같은 범용 함수를 만들고 여기에 예외 처리를 철저하게 만들자

CHAPTER 2. 고급 HTML 분석
복잡한 웹 페이지에서 필요한 정보를 얻기 위해 원하지 않는 정보를 깎아내자
2.1 닭 잡는 데 소 잡는 칼을 쓸 필요는 없습니다.
- 이 장에서 소개하는 테크닉을 부주의하게 사용한다면 코드는 디버그하기 어려워지거나, 취약해지거나, 혹은 둘 다가 될 수도 있다.
- 사이트 관리자가 사이트를 조금만 수정하더라도 웹 스크레이퍼의 동작이 멈출 수 있다.
- 고급 HTML 분석을 쓰지 않고 필요한 결과를 얻을 수 있는 방법도 있다.
1) '페이지 인쇄' 같은 링크를 찾아보거나, 더 나은 HTML 구조를 갖춘 모바일 버전 사이트를 찾아보십시오
2) 자바스크립트 파일에 숨겨진 정보를 찾아보십시오
3) 중요한 정보는 페이지 타이틀에 있을 때가 대부분이지만, 원하는 정보가 페이지 URL에 들어 있을 때도 있습니다.
4) 원하는 정보가 오직 이 웹사이트에만 있다면 할 수 있는 일이 더는 없을 수 있습니다. 그렇지 않다면, 이 정보를 다른 소스에서 가져올 수 는 없는지 생각해보십시오. 다른 웹사이트에 같은 데이터가 있지는 않을까요? 이 웹사이트에 있는 데이터가 혻 ㅣ다른 웹사이트에서 수집한 것은 아닐까요?
- 데이터가 깊숙이 파묻혀 있거나 정형화되지 않았을수록, 곧바로 코드부터 짜서는 안 됩니다. 심호흡을 하고 대안이 없는지 생각해보십시오
2.2 다시 BeautifulSoup
- 이 섹션에서는 다음 내용을 알아 본다.
1) 속성을 통해 태그를 검색하는 법
2) 태그 목록을 다루는 법
3) 트리 내비게이션을 분석하는 법

2.2.1 find()와 findAll()
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
tag : 태그 이름인 문자열을 넘기거나, 태그 이름으로 이루어진 파이썬 리스트를 넘긴다.


attributes : 속성으로 이루어진 파이썬 딕셔너리를 받고, 그중 하나에 일치하는 태그를 찾는다.


recursive : 불리언(boolean) : 문서에서 얼마나 깊이 찾아 들어가고 싶은지 지정
: true - 자식, 자식의 자식을 검색
: false - 최상위 태그만 찾는다.
: findAll은 기본적으로 True
text : 일치하는 텍스트 콘텐츠를 찾는다(ex: count)

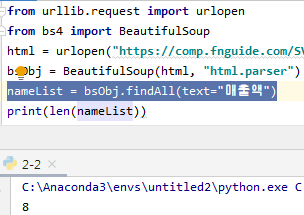
limit : findAll만 쓰임, 페이지의 항목 처음 몇 개에만 관심이 있을 때 사용
: find는 기본적으로 1
keyword : 특정 속성이 포함된 태그를 선택할 때 사용


2.2.2 기타 BeautifulSoup 객체
- NavigableString 객체 : 태그 자체가 아니라 태그 안에 들어 있는 텍스트를 나타냄
- Commnet 객체 : 주석 태그 안에 들어있는 HTML주석(<!-- -->)을 찾는 데 사용
#코멘트는 실제 구글링 해봤는데 쉽게 사용되는 것처러 보이진 않음
2.2.3 트리 이동
- 트리 내비게이션이 필요한 이유? 문서 안에서의 위치를 기준으로 태그를 찾을 때
- 자식과 자손
: 자식은 항상 부모보다 한 태그 아래
: 자손은 조상보다 몇 단계든 아래 가능
: 모든 자식은 자손이지만 모든 자손은 자식이 아님


- 형제 다루기
: next_siblings() 함수 <> previous_siblings() 함수
: 객체는 자기 자신의 형제가 될 수 없다.
: 이 함수는 다음 형제만 가져온다.
- 아래 예제는 첫 번재 타이틀 행을 제외한 모든 제품 행을 조회한다.


- 스크래이퍼를 더 견고하게 만들려면 항상 태그를 가능한한 명확하게 선택하는 것이 최선이다.
- 가능하다면 태그 속성을 이용하라.
- 부모 다루기
: 일반적으로 HTML 페이지에서 데이터를 수집할 목적으로 살펴볼 때는 보통 맨 위 계층에서 시작해 원하는 데이터까지 찾아들어가지만 그 반대도 필요할 수 있다.

|
위 테스트 예제의 HTML 트리구조와 호출 순서 <tr> - <td> - <td> - <td> ③ - "$15.00 ④ - <img src="../img/gifts/img1.jpg"> ① ① 이미지 선택 ② 부모 태크<td> 선택 ③ 2번의 <td>의 previus 태그 선택 <td> ④ 태그에 들어 있는 텍스트($15.00) 선택 |
2.3 정규표현식
- 유래 : 정규 문자열을 식별하는 데 쓰이는 데서 유래
- 문자열이 주어진 규칙에 일치하는지, 일치하지 않는지 판단할 수 있다.
ex) 전화번호, 이메일 주소 등
- 정규 문자열 : 선형 규칙을 연달아 적용해 생성할 수 있는 문자열
1) 글자 a 를 최소한 한 번 쓰시오
2) 그 뒤에 b를 정확히 다섯 개 쓰시오
3) 그 뒤에 c를 짝수 번 쓰시오
4) 마지막에 d가 있어도 되고 없어도 됩니다.
=> aa*bbbbb(cc)*(d | )
(정규식 테스트 웹 : https://www.regexpal.com/)
- (고전)이메일 식별 : [A-Za-z0-9\._+]+@[A-Za-z]+\.(com|org|edu|net)
- 아무것도 없는 상태에서 정규 표현식을 만들 때는
목표하는 문자열이 어떤 형태인지 정확하게 나타내는 단계의
목록을 만드는 것으로 시작하는게 좋다.
- 정규 표현식은 언어마다 다르다.
2.4 정규 표현식과 BeautifulSoup
- 모든 이미지 태그를 가져오면 문제가 있다
: 로그 등의 불필요한 이미지
: 숨은 이미지, 공백 유지와 요소 정렬용 빈 이미지
- 페이지 레이아웃에 따라 노출여부가 달라질 수도 있다.
- 해결책 : 태그 자체를 식별하는 무언가를 찾는다.

2.5 속성에 접근하기
- 태그 객체에서 속성 목록에 접근할 수 있다.
: myTag.attrs
: myImgTag.attrs['src'] - 이미지 소스 위치 찾기
2.6 람다lambda 표현식
- 람다 표현식 : 다른 함수에 변수로 전달되는 함수이다.
ex) f(g(x), y) or f(g(x), h(x))
- 웹 스크레이핑에서 활용
: BeautifulSoup에서는 특정 타입의 함수를 findAll 함수에 매개변수로 넘길 수 있다.
ex) soup.findAll(lambda tag: len(tag.attrs) == 2) //속성이 2개인 태그들을 찾아낸다.

2.7 BeautifulSoup를 넘어
- lxml 라이브러리
: HTML, XML 문서를 모두 파싱
: 거의 C언어로 만들어진 저수준 라이브러리
- HTML 파서
: 파이썬 내장 파싱 라이브러리
CHAPTER 3. 크롤링 시작하기
- 웹 크롤링의 핵심은 재귀
- 웹 크롤러는 반드시 대역폭에 세심한 주의를 기울여야 하며, 타겟 서버의 부하를 줄일 방법을 강구해야 한다.
3.1 단일 도메인 내의 이동
- 위키 백과의 여섯 다리를 풀기

- 원하지 않는 내용들도 결과로 출력 : 사이드바, 푸터, 링크, 카테고리, 토론 페이지 등
- 항목 페이지를 가리키는 링크에는 다른 내부 페이지를 가리키는 링크와 비교되는 세 가지 공통점을 찾을 수 있다.
1) 이 링크들은 id가 bodyContent인 div 안에 있다.
2) URL에는 세미콜론이 포함되어 있지 않다.
3) URL은 /wiki/로 시작한다.

- 위 스크립트는 현실적으로는 쓸모가 없다. 다음과 같은 형태로 변경
1) /wiki/<article_name> 형태인 위키백과 항목 URL을 받고, 링크된 항목 URL 목록 전체를 반환하는 getLinks 함수
2) 시작 항목에서 getLinks를 호출하고 반환된 리스트에서 무작위로 항목 링크를 선택하여 getLinks를 다시 호출하는 작업을, 프로그램을 끝내거나 새 페이지에 항목 링크가 없을 때까지 반복하는 메인 함수

3.2 전체 사이트 크롤링
- 사이트 전체를 이동하는 웹 스크레이퍼의 여러가지 장점
1) 사이트맵 생성
ex) 웹사이트 재설계 비용 요청 단, 현재 사용 중인 콘텐츠 관리 시스템 내부에 접근 권한을 주지 않음. 공개된 사이트맵도 없는 상황
-> 사이트 전체를 이동하는 크롤러를 이용하여 내부 링크를 모두 수집
-> 그 페이지들을 사이트의 실제 폴더 구조와 똑같이 정리
->> 누락 페이지 발견 및 재 설계 페이지양과 컨텐츠 양 산출 가능
2) 데이터 수집
: 사이트를 철저히 크롤링하려면 보통 홈페이지 같은 최상위 페이지에서 시작해, 그 페이지에 있는 내부 링크를 모두 검색한다. 검색한 링크를 모두 탐색하고, 거기서 다시 링크가 발견되면 크롤링 다음 라운드가 시작된다.
: 같은 페이지를 두 번 크롤링하지 않으려면 발견되는 내부 링크가 모두 일정한 형식을 취하고, 프로그램이 동작하는 동안 계속 유지되는 리스트에 보관하는 게 대단히 중요하다.
: 새로운 링크만 탐색하고 거기서 다른 링크를 검색해야 한다.
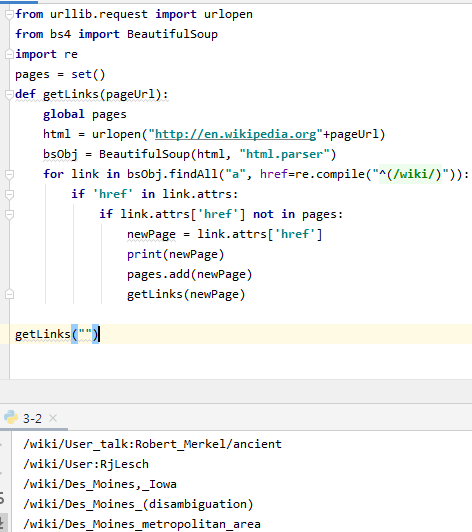
1. getLinks에 빈 URL을 넘겨 호출
2. 함수 내부에서 빈 URL 앞에 "http://..."을 붙여 위키백과 첫 페이지 URL로 변경
3. 첫 번째 페이지의 각 링크를 순회, 전역 변수인 pages에 값이 있는지 확인
4. 없으면 리스트에 추가, 화면 출력, getLinks 함수 재귀적 호출
CAUTION_ 재귀에 관한 경고
파이썬은 기본적으로 재귀 호출을 1,000회로 제한, 위 예제는 멈춘다.
-> 재귀 카운터 삽입 등
내부 링크를 일정한 규칙에 따라 생성할 경우 URL이 이상해 질 수 있음(엉뚱한 반복 등)
-> URL체크 로직 추가 등
3.2.1 전체 사이트에서 데이터 수집
- 가장 먼저 사이트의 페이지 몇 개를 살펴보며 패턴을 찾는다.
ex) 위키백과
: 어떤 페이지이든 제목은 항상 h1 태그 안에 있으며 h1 태그는 페지당 하나만 존재
: 모든 바디 텍스트는 div#bodyContent 태그에 있다.
: 편집 링크는 항목 페이지에만 존재

h1 타이틀 출력
텍스트 콘텐츠 출력(파일 페이지 제외)
편집 버튼 출력
3.3 인터넷 크롤링
- 도메인간 데이터 분석을 우해서는인테넛의 무수히 많은 페이지에서 데이터를가져오고 해석할 수 있는 크롤러가 필요
- 단순히 외부 링크를 닥치는 대로 다라가는 크롤러를 만들기 전에 먼저 자신에게 질문을 해보자
: 내가 수집하려 하는 데이터는 어떤 것인가?
-> 정해진 사이트 몇 개만 수집하면 되는가? (이런 경우, 거의 틀림없이 더 쉬운 방법이 있다.)
-> 그런 사이트가 있는지조차 몰랐던 사이트에도 방문해야 하는가?
: 크롤러가 특정 웹사이트에 도달하면, 즉시 새 웹사이트를 가리키는 링크를 따라가야 할까? 아니면 한동안 현재 웹사이트에 머물면서 파고들어야 할까?
: 특정 사이트를 스크랩에서 제외할 필요는 없나? 비 영어권 콘텐츠도 수집해야 할까?
: 만약 크롤러가 방문한 사이트의 웹마스터가 크롤러의 방문을 알아차렸다면 나 자신을 법적으로 보호할 수 있을까?

책 예제 해당 라인 수정했음
기본 사이트로부터 외부 링크에서 외부 링크로 무작위로 이동
- 사이트 전체에서 외부 링크를 검색하고 각 링크마다 메모를 남긴다.

- 실제 코드를 작성하기 전에 그 코드가 무슨 일을 하는지 다이어그램을 그려보거나 메모해보는 습관을 들여라.
3.4 스크래파이를 사용한 크롤링
- 스크래파이(Scrapy) : 웹사이트의 링크를 찾아서 분석하고, 도메인이나 도메인 목록 크롤링 작업을 쉽게 해주는 파이썬 라이브러리

(책에서 예상한 결과와 다른 결과가 출력되었다.)
- 해당 예제는 start_urls에 있는 두 페이지로 이동해 정보를 수집한 후 종료
CHAPTER 4. API 사용
- API는 본질에서 다른 여러 애플리케이션 사이에 간편한 인터페이스를 제공
- API는 서로 정보를 공유해야 하는 소프트웨어 사이에서 국제어 구실을 하도록 디자인 된 것
- API를 사용하는 건 웹스크레이핑이 아니라고 생각하는 사람이 대부분이지만, 양자가 거의 같은 테크닉(HTTP 요청 보내기)을 사용해 비슷한 결과(정보 얻기)를 추구합니다. 둘은 상호 보완적일 때가 많습니다.
4.2 공통 표기법
4.2.1 메서드
- GET : 브라우저의 주소 표시줄을 통해 웹사이트에 방문할 때 쓰는 방법, 웹 서버에 정보를요청할 때 쓰는 방법
- POST : 폼을 작성하거나, 서버에 있는 스크립트에 정보를 보낼 때 사용, API에서 POST요청을 보내는 건 그 정보를 데이터베이스에 저장하라고 요청을 하는 것
- PUT : 객체나 정보를 업데이트할 때 사용
- DELETE : 어떤 객체를 삭제할 때 사용, 주로 정보의 배포가 목적인 공용API 에서는 DELETE 메서드를 쓰는 경우가 별로 없다.
4.2.2 인증
- API 인증은 일반적으로 일종의 토큰을 사용하며 API를 호출할 때마다 이 토큰이 웹 서버에 전송
- 토큰은 요청 자체의 URL에 넣어서 보낼 수도 있고, 요청 헤더에서 쿠키를 통해 보낼 수도 있다.
4.3 응답
- 응답 타입
1) XML (Extensible Markup Language)
2) JSON (JavaScript Object Notation)
4.3.1 API 호출
- API 호출 문법은 API에 따라 크게 다르지만, 몇 가지 표준적인 부분도 존재
- GET 요청으로 데이터를 가져올 때, URL경로는 데이터를 어떻게 찾아가는지를 나타내고 쿼리 매개변수는 일종의 필터 또는 검색에 사용할 추가 요청 구실을 한다.
4.4 에코 네스트
- 사용 불가
4.5 트위터
- 사용 제한 : 15분사이 15번호출, 15분 사이 180번 호출
(자세한 사용 제한은 twitter 홈페이지 참고)
- 계정이 필요하며, 개발자 사이트에 '애플리케이션'을 등록해야 함
> 복잡해서 일단 보류 > 있다는 것만 알아 두자
4.6 구글 API
- 다양한 API 제공
- 레퍼런스 페이지 : 제품페이지, API콘솔 페이지
- 대부분 무료지만 일부 API 사용료 지불
4.6.1 시작하기
- 구글 계정 생성
- API 콘솔 페이지에서 사용자 인증 정보 등록
https://console.developers.google.com/
Google Cloud Platform
하나의 계정으로 모든 Google 서비스를 Google Cloud Platform을 사용하려면 로그인하세요.
accounts.google.com

- 책의 예제와 현재 구글api 상태가 많이 상이함. 따라하려면 별도로 자료를 찾아서 해야해 보임
- Place API 를 등록하고 사용해봄


- input 값을 다른 곳으로 변경
https://maps.googleapis.com/maps/api/place/findplacefromtext/json?input=seoul&...생략...

4.7 JSON 파싱
- JSON 객체는 딕셔너리로, JSON 배열은 리스트로, JSON 문자열은 문자열로 변환한다.
- 책 속 예제는 동작하지 않는다. api요청 자체가 동작하지 않아서 그럴것으로 보임
- 사이트 주소도 바꼈고 다른 사이트에 통합된 것으로 보인다?
- 아래와 같이 사용할 수 있는 것만 확인

4.8 모든 것을 하나로
- API에서 얻은 데이터와 웹 스크레이핑을 결합
- 위키백과 개정 내역 페이지를 크롤링하고 IP주소를 찾아내는 스크립트

- 해당 예제와 freegeoip 의 예제를 합쳐야 하는데 동작하지 않으므로 있다 정도만 알자
CHAPTER 5. 데이터 저장
5.1 미디어 파일
- 미디어 파일을 저장하는 방법 2가지 : 참조를 저장, 파일 자체를 저장
참조 저장시의 장/단점
장점
: 빠른 동작, 적은 대역폭 요구
: 컴퓨터의 공간 확보
: 코드 생성 용이
: 적은 호스트 서버 부하
단점
: 핫링크 포함시 말썽이 생실 소지가 많다.
: 사용할 미디어 파일을 모르는 서버에 맡김
: 외부 파일은 변경 될 수 있음


인데 왜 한개 밖에 다운로드를 하지 않는가?????!!!!
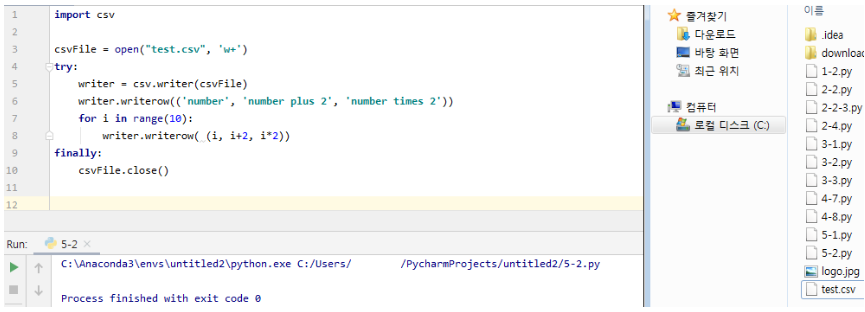
5.2 데이터를 CSV로 저장
- CSV(Comma-separated values) : 스프레드시트 데이터를 저장할 때 가장 널리 쓰임
- 각 행은 줄바꿈 문자로 구문
- 각 열은 쉼표로 구분

5.3 MySQL
5.3.1 MySQL설치
5.3.2 기본 명령어

5.3.3 파이썬과의 통합

- MySQL 데이터베이스에 유니코드 대비 캐릭터셋 세팅

- 최종 테스트 결과


5.4 이메일
CHAPTER 6. 문서 읽기
- 웹스크레이핑에서 '문서'도 읽는 이유
: 인터넷은 정보의 집합이며 HTML 파일은 종종 그 프레임 구실을 할 뿐입니다. 텍스트와 PDF, 이미지, 비디오, 이메일, 그 외 수많은 문서 타입을 읽지 못한다면 데이터의 상당부분을 놓치는 것이기 때문이다.
6.1 문서 인코딩
- 문서 인코딩은 애플리케이션이 그 문서를 읽는 방법을 지정
- 모든 문서는 기본적으로 0과 1로 인코딩되어 있다.
6.2 텍스트

- 단서로 쓸 HTML 태그가 없으므로, 실제 필요한 텍스트와 쓸모없는 텍스트를 구분하기가 쉽지 않다.
- 텍스트 파일에서 정보를 추출할 때 부딪히는 어려운 문제
6.2.1 텍스트 인코딩과 인터넷
- 인코딩 타입과 개관 : 사이트 스크랩을 시작하기 전에 미리 인코딩을 체크하는 것이 중요
- 인코딩 예제 : 위 예제는 영어 텍스트는 잘 동작하지만, 러시아어나 아라비아어 등에서 문제 발생


- 파이썬은 이문서를 ASCII로 읽으려 했고, 브라우저는 다른 캐릭터셋으로 문서를 읽으려 했다는 것


- 텍스트가 어떤 인코딩을 가졌는지 정확하게 판단하는 건 불가능
- HTML 페이지의 인코딩은 보통 <head> 내부의 태그에 존재
- 국제적 사이트에 관심이 있다면, 해당 메타 태그를 찾아보고 이 태그에서 지정한 인코딩 방법을 써서 페이지 콘텐츠를 읽는게 좋다.
6.3 CSV


- DictReader 함수 사용으로 처리

6.4 PDF
- 예제 주소 변경 됨 https://github.com/jaepil/pdfminer3k

6.5 마이크로소프트 워드와 .docx



PART II. 고급 스크레이핑
CHAPTER 7. 지저분한 데이터 정리하기
7.1 코드로 정리하기
- n-그램 : 텍스트나 연설에서 연속으로 나타난 단어 n개



- i와 a를 제외한 한 글자 제외
- 위키백과 인용 표시인 대괄호 감싼 숫자 제외
- 구두점 제외

7.1.1 데이터 정규화
- n-그램 사용. 단, 중복이 많다
- 파이썬 딕셔너리는 정렬되지 않는다
: 파이썬의 collections 라이브러리의 OrderDict로 해결

기존 예제는 동작안함. ngrams.item() 에서 item()삭제하면 돌긴 도나 결과 다름
7.2 사후 정리
7.2.1 오픈리파인
CHAPTER 8. 자연어 읽고 쓰기
8.1 데이터 요약
8.2 마르코프 모델
8.3 자연어 툴킷
8.4 추가자료
CHAPTER 9. 폼과 로그인 뚫기
9.1 파이썬 requests 라이브러리
9.2 기본적인 폼 전송
9.3 라디오 버튼, 체크박스, 기타 필드
9.4 파일과 이미지 전송
9.5 로그인과 쿠키 처리
9.6 기타 폼 문제
CHAPTER 10. 자바스크립트 스크레이핑
10.1 자바스크립트에 관한 간단한 소개
10.2 Ajax와 동적 HTML
10.3 리다이렉트 처리
CHAPTER 11. 이미지 처리와 텍스트 인식
11.1 라이브러리 개관
11.1.1 필로
11.1.2 테서랙트
11.1.3 넘파이
11.2 형식이 일정한 텍스트 처리
11.3 CAPTCHA 읽기와 테서랙트 훈련
11.4 CAPTCHA 가져오기와 답 보내기
CHAPTER 12. 스크레이핑 함정 피하기
12.1 스크레이핑의 윤리에 관해
12.2 사람처럼 보이기
12.3 널리 쓰이는 폼 보안 기능
12.4 사람처럼 보이기 위한 체크리스트
CHAPTER 13. 스크레이퍼로 웹사이트 테스트하기
13.1 테스트 입분
13.2 파이썬 unitteset
13.3 셀러니움을 사용한 테스트
13.4 unittest vs 셀러니움
CHAPTER 14. 원격 스크레이핑
14.1 원격 서버를 쓰는 이유
14.2 토르
14.3 원격 호스팅
14.4 추가 자료
14.5 미래를 향해
'책을 읽.쓰.' 카테고리의 다른 글
| <주식시장은 어떻게 반복되는가> [필사][리뷰][정리](20200330) (6) | 2020.03.09 |
|---|---|
| <전문가를 위한 오라클 데이터베이스 아키텍처> (0) | 2020.02.26 |
| <리눅스 프로그래밍 : 원리와 실제> (0) | 2020.02.18 |
| <재무제표 모르면 주식투자 절대로 하지마라> (8) | 2020.02.11 |
| <Operating System Concepts> (0) | 2020.02.07 |